Time series data has the special property of changing with time - observations for a single process or subject have a chronological order. Data points are therefore correlated with each other and violate the independent indentically distributed assumption that many regression-type models rely upon. Thus, time series data requires new methods for its analysis. One common class of models is the ARIMA model, or the auto-regressive integrated moving average model. It makes the important assumption of stationarity.
Stationarity
Stationarity - at least in the context of time series analysis - is the property that a time series is independent of time. Quantitatively speaking, this means that the statistical properties such as mean and variance are constant with respect to time. (Note that this refers to weak stationarity, whereas strong stationarity refers to the more stringent property that the distribution of time series data holds constant through time. In most analysis of time series, however, weak stationarity is sufficient.)
In other words, stationarity is achieved if the lags, or data at different points in time as the current point of reference, does not depend on time. One rough way to verify this is to simply plot the data. This notebook will be focusing on stock price data.
import yfinance as yf
import numpy as np
import scipy.stats as stats
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
import warnings
# pull monthly S&P500 data from the past 5 years
data = yf.download(tickers = ['^GSPC'], start = '2016-09-01', end = '2021-09-01', period = '1mo', interval = '1mo',
group_by = 'ticker', auto_adjust = True, prepost = False, threads = True, proxy = None)
# remove any rows with NAs
data = data.dropna(axis = 0)
plt.plot(data['Close'])
plt.title("SP500 Closing Price")
plt.show()
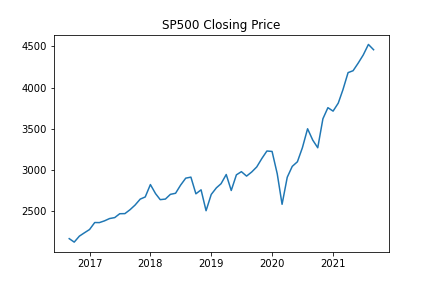
One can easily tell that the value of the S&P 500 index is not stationary. As time passes, the mean and variance are surely non-constant as evident by the general upward trend.
Stationarity can also be more closely checked using hypothesis testing. One common choice is the Augmented Dickey–Fuller(ADF) test, which attempts to reject the null hypothesis that a time series has a unit root(series with unit roots are not stationary). An alternative to the ADF test is the Kwiatkowski–Phillips–Schmidt–Shin (KPSS) test, which attempts to reject the null hypothesis that a series is stationary. Both tests have their pros and cons, and other alternatives can be found in this Cross Validated post.
adf_test = dict(zip(['Test Statistic','p-value','#Lags Used','#Observations Used'],
list(sm.tsa.stattools.adfuller(data['Close'], autolag='AIC')[:4])))
print("ADF:", adf_test)
kpss_test = dict(zip(['Test Statistic','p-value','Lags Used'],
list(sm.tsa.stattools.kpss(data['Close'], nlags='auto')[:3])))
print("KPSS:", kpss_test)

The ADF test fails to reject the null hypothesis that there is a unit root and the KPSS test rejects the null hypothesis that the series is stationary. Thus we can be confident that our data is indeed non-stationary.
In some cases, approximate stationarity can be achieved using simple log or square root transforms, which shrink changes in the mean and variance. However, a more common technique to impose stationarity is that of differencing.
Differencing
Differencing is the technique of turning a series of values into a series of changes in values. This is done by subtracting each data point by its immediate predecessor(or a data point \(k\) units of time prior as seen fit). Thatis, for a given time series \(X = \{x_0, x_1, \ldots, x_n\}\) the differenced series is then \(Y = \{x_i - x_{i-1}\}^{n}_{i = 1}\)
Differencing can be performed more than once, where a series differenced \(k\) times is refered to as a \(kth\)-order differenced series. Intuitively, a first-order difference removes linear trends, a second-order difference removes quadratic trends, and so on. A differenced series can be easily “undifferenced” by a corresponding number of cumulative sums.
def diff(seq, lag = 1):
return(seq[lag:] - seq[:(len(seq) - lag)])
plt.plot(diff(data['Close'].values))
plt.hlines(0, xmin = 0, xmax = len(diff(data['Close'].values)))
plt.title("SP500 First-order Difference")
plt.show()
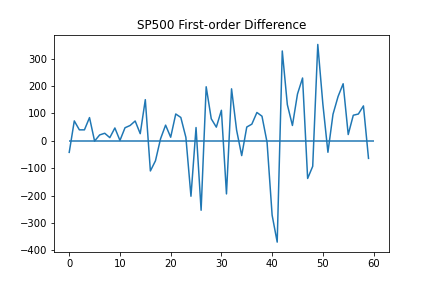
It seems that a first-order difference of the data is enough to reach approximate stationarity. This can again be verified using the ADF and KPSS tests.
adf_test = dict(zip(['Test Statistic','p-value','#Lags Used','#Observations Used'],
list(sm.tsa.stattools.adfuller(diff(data['Close'].values), autolag='AIC')[:4])))
print("ADF:", adf_test)
kpss_test = dict(zip(['Test Statistic','p-value','Lags Used'],
list(sm.tsa.stattools.kpss(diff(data['Close'].values), nlags='auto')[:3])))
print("KPSS:", kpss_test)

Another important property of time series data is autocorrelation, or self correlation.
Autocorrelation
Autocorrelation (also known as serial correlation) measures the correlation between a series and itself after being lagged(e.g. shifted). It’s a useful measure for uncovering any overall linear trends in the series over time, especially any that remain after the series is sufficiently differenced(overdifferencing a series can increase the variance of the time series, making accurate forecasts more difficult).
Plotting the autocorrelation function(ACF) of a time series is a quick way to spot any significant trends in the data. Models aim to eliminate significant autocorrelations, or those that fall outside of the critical region. In this case, the critical region is defined by \(\pm 1.96 \sqrt{n}\), where \(n\) is the number of observations in the series.
sm.graphics.tsa.plot_acf(data['Close'])
plt.show()
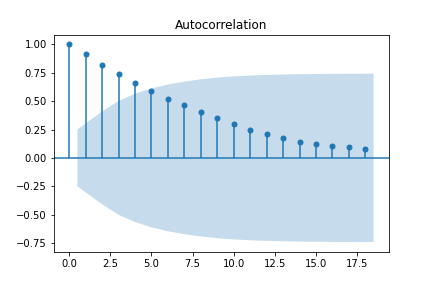
Looking at the ACF of the undifferenced series, observations are strongly correlated with those that immediately follow, with the autocorrelation decaying the more lags are introduced. It isn’t until about \(5\) lags that it dips within the critical region.
sm.graphics.tsa.plot_acf(diff(data['Close'].values))
plt.show()
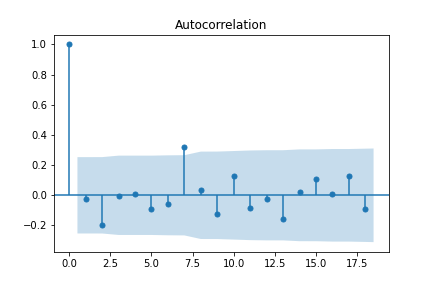
After differencing, most of the autocorrelations fall within the critical region - save for the one at \(7\) lags. A reasonable assumption would be to difference one more time.
sm.graphics.tsa.plot_acf(diff(diff(data['Close'].values)))
plt.show()
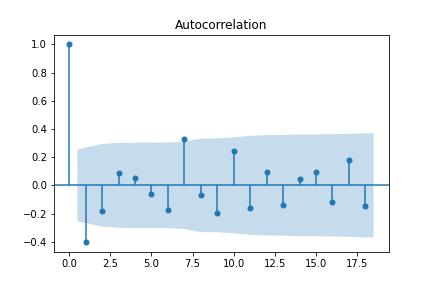
Unfortunately, repeatedly differencing won’t solve all our autocorrelation problems. This is an example of overdifferencing, which exacerbates autocorrelations (in this case, almost across the board). Rather than overdifferencing, remaining significant autocorrelations can be dealt with using the correct choice of model parameters.
While the ACF is useful in identifying remaining trends, it can also be redundant in the trends it reveals. For example, the ACF for sinusoidal data is also sinusoidal, making it less than useful.
sindata = np.cos(np.arange(0, 100)*np.pi / 3)
sm.graphics.tsa.plot_acf(sindata)
plt.show()
# plot ACF of differenced data
sm.graphics.tsa.plot_acf(diff(sindata))
plt.show()
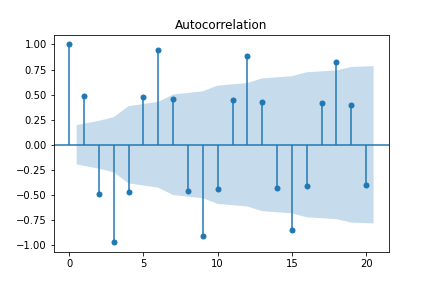
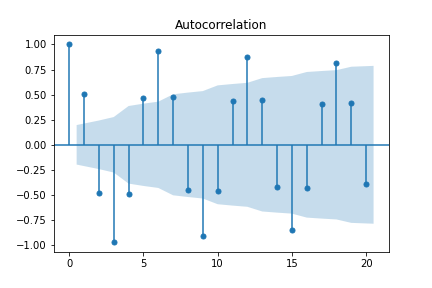
Because of its cyclic/sinusoidal nature, differencing the data has no effect on the ACF. In order to reduce redundancy in the ACF, one can turn to the partial autocorrelation function (PACF).
Partial Autocorrelation
The partial autocorrelation function(PACF) tells a similar story to the ACF. Both reveal trends in a series, but they differ in computed values. While autocorrelation has cyclical autocorrelations when the series is cyclical, the partial autocorrelation corrects for intermediate lags, causing the correlations to decay faster. One way the partial autocorrelation can be computed is calculating the correlation of two residuals obtained after regressing \(x_{k+1}\) and \(x_1\) on the intermediate observations \(x_2, \ldots, x_k\) (Peter and Richard (2009)). We can immediately see the difference by plotting the PACF.
# used ywm because default method was acting up
sm.graphics.tsa.plot_pacf(sindata, method = 'ywm')
plt.show()
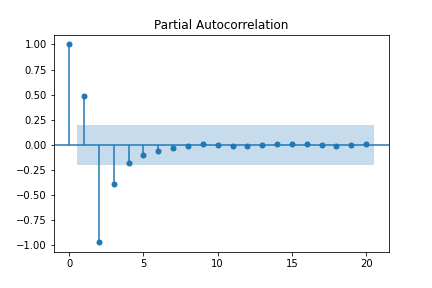
Rather than a cyclic behavior like the ACF, PACF quickly decays due to the redundant correlations being accounted and adjusted for. While this may sound like PACF makes ACF useless, both metrics have their respective uses in the ARIMA model, which will finally be discussed next.
ARIMA = AR + I + MA
ARIMA is the combination of three components: autoregression(AR), integrated (I), and moving-average(MA). We’ve actually already covered the I component - integrated refers to differencing.
A quick note about differencing: while it is certainly possible to manually difference time series data before fitting a model to it, it is usually preferable to allow the model to take care of it. This mitigates the chances of human error and makes it easier to compute things like fitted values and forecasts(which requires undifferencing the data). What’s more, fitted values of already differenced data can’t be undifferenced to yield fitted values of undifferenced data. Basically, leave the differencing to the function(see this Cross Validated post for a more complete discussion).
AR Models
The second component to be discussed is the autoregressive (AR) model. As the name suggests, an autoregressive model uses previous lags as predictors of the next observation, with AR(\(p\)) referring to an AR model fitted with \(p\) lags:
\[\begin{align} y_t = \phi + \phi_{t-1} y_{t-1} + \cdots + \phi_{p-t} y_{p-t} + \epsilon_t \end{align}\]where \(\epsilon_t\) is assumed to have mean \(0\). On the surface, the AR model resembles a linear regression model(with independent predictors swapped out for lags). In fact, the coefficients \(\phi_i\) can be solved for using the normal equations. This unique setup also allows for different methods of solution, one popular example being the Yule-Walker equations (in fact, the computations required by the Yule-Walker equations make computing the PACF rather simple, see these lecture notes for details).
Note that the extent of forecasting is limited by the order of the model, as each new prediction is fed into the prediction of the next one. For example, in an AR(1) model, we can only forecast one step ahead, as any steps afterward are not dependent on the dataset and eventually decay to the mean (showing this empirically is left to the reader).
To determine an approximate order \(k\) for an AR process, the PACF is often used. In theory, an AR(\(p\)) process should see a steep cutoff in partial autocorrelation for lags greater than \(p\), as the first \(p\) lags fully describe the current observation and once adjusted for, leave the correlation close to \(0\).
sm.graphics.tsa.plot_pacf(diff(data['Close'].values), method = 'ywm')
plt.show()
From the PACF plot of the differenced series, it seems there is a significant value at lag \(7\). Thus, AR(\(7\)) is a candidate model, albiet a bit complex for such a small dataset.
# p=7, d=1, q=0(not part of AR model)
ar = sm.tsa.arima.ARIMA(data['Close'].values, order = (7,1,0))
ar_res = ar.fit()
print(ar_res.summary())
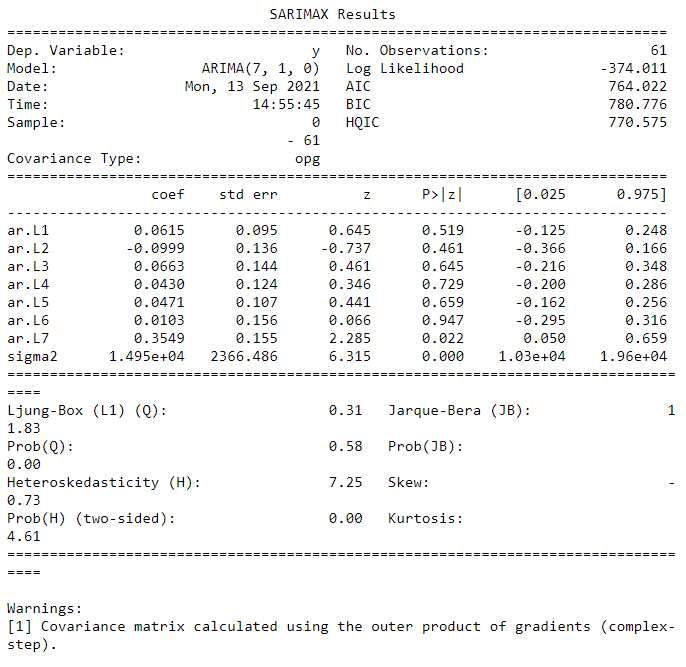
Looking first at the coefficients, it’s a bad sign that almost all of them are nonsignificant, that is there is no significant difference between a coefficient of zero and a nonzero coefficient. In other words, the model is too complex and probably not much different from a random walk model(or AR(\(0\)) model). For a detailed description of the interpretation of the other statistics and tests provided in the output summary, refer to this useful Analyzing Alpha blog post.
Although easily interpretable, this method of evaluating individual parameters can be difficult to quantify. Two other ways of assessing a model’s fit and performance can be done through the AIC/BIC and mean absolute percentage error (MAPE) measures. AIC/BIC quantifies how well a model fits the data it is trained on, with lower values corresponding to better fits, but requires background knowledge or other models for comparison. MAPE, on the other hand, provides an easily understandable measure of how a model performs in terms of accurate predictions.
The MAPE can be computed using a rolling window of data and repeatedly fitting a new model to it.
with warnings.catch_warnings():
warnings.simplefilter('ignore')
forecasts = []
for i in range(7, len(data['Close'].values)):
model = sm.tsa.arima.ARIMA(data['Close'].values[:i], order=(7,1,0))
model_res = model.fit()
yhat = model_res.forecast()[0]
forecasts.append(yhat)
print(np.abs((data['Close'].values[7:] - forecasts) / data['Close'].values[7:]).sum() / len(forecasts))

While an underwhelming result, this demonstrates that analyzing the PACF is not a perfect solution to fitting an AR model. One should also be wary of fitting small datasets to higher order AR models, as overfitting is likely to occur.
MA Model
The third component is the moving-average (MA) model. Not to be confused with the moving average(computing the average of a rolling window), this model consists of a linear combination of previous error terms structured similarly to the AR model. A MA(\(q\)) refers to an MA model fitted with \(q\) lags.
\[\begin{align} y_t = \mu + \theta_{t-1}\epsilon_{t-1} + \cdots + \theta_{t-q}\epsilon_{t-q} \end{align}\]where \(\mu\) is the mean of the process and \(\epsilon_i\) is the white noise error term of the \(i\)th lag. Because the error terms are not observable, other computational methods must be used to solve for the coefficients.
To determine the approximate order of an MA process, one can utilize the ACF function. In theory, there should be a steep cutoff in the autocorrelation for any lags larger than \(q\), as the white noise terms are assumed to be i.i.d. and therefore independence will ensure no correlation.
sm.graphics.tsa.plot_acf(diff(data['Close'].values))
plt.savefig('acfDiffData.png')
plt.show()
From the ACF plot, it seems an MA(\(7\)) may be appropriate for the data. This order is also suspiciously high for such a small set of data.
ma = sm.tsa.arima.ARIMA(data['Close'].values, order = (0,1,7))
ma_res = ma.fit()
print(ma_res.summary())
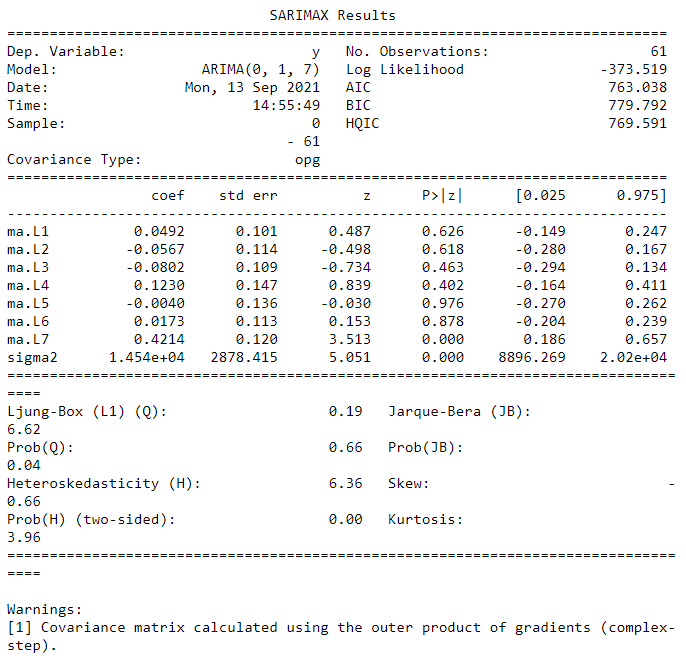
The MA(\(7\)) model seems to be a better fit than the AR(\(7\)) model, sporting more significant coefficients and a lower AIC/BIC score. However, it still seems to overfit the data as half the coefficients are nonsignificant.
with warnings.catch_warnings():
warnings.simplefilter('ignore')
forecasts = []
for i in range(7, len(data['Close'].values)):
model = sm.tsa.arima.ARIMA(data['Close'].values[:i], order=(0,1,7))
model_res = model.fit()
yhat = model_res.forecast()[0]
forecasts.append(yhat)
print(np.abs((data['Close'].values[7:] - forecasts) / data['Close'].values[7:]).sum() / len(forecasts))
temp = pd.DataFrame(data = {'actual': data['Close'].values[7:].copy(), 'pred': forecasts})
print((np.abs(temp['actual'] - temp['pred']) / temp['actual']).mean())

The forecasting yielded at least a couple NaNs, which may suggest overfitting(see this Cross Validated post for possible issues). This isn’t a good sign, but perhaps combining it with the AR(\(7\)) model will alleviate some issues.
If we only look at the non-NaN predictions, the MAPE score is slightly lower than the AR(\(7\)), but not by much. This reflects the slight decrease in the AIC/BIC and could very well be a result of variance or noise in the specific training data being used.
Fitting ARIMA
The AR and MA models provide different motivations and interpretations for describing and forecasting a time series. Both have their upsides and downsides. Perhaps combining them into a single model will yield the best of both worlds. If one refers to the ACF and PACF plots to decide the coefficients, fitting an ARIMA(\(7,1,7\)) is a reasonable line of action.
arma = sm.tsa.arima.ARIMA(data['Close'].values, order = (7,1,7))
arma_res = arma.fit()
print(arma_res.summary())
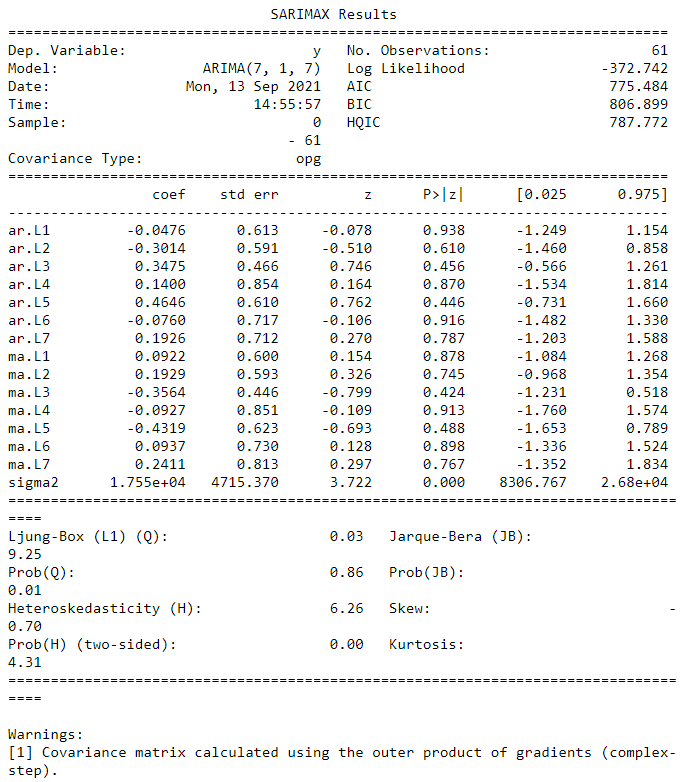
Unfortunately, combining the two models did not do much to improve the fit, in fact the AIC/BIC scores are higher than those of the MA(\(7\)) model. This makes sense since AR(\(7\)) had a rather high AIC/BIC to begin with.
with warnings.catch_warnings():
warnings.simplefilter('ignore')
forecasts = []
for i in range(7, len(data['Close'].values)):
model = sm.tsa.arima.ARIMA(data['Close'].values[:i], order=(7,1,7))
model_res = model.fit()
yhat = model_res.forecast()[0]
forecasts.append(yhat)
print(np.abs((data['Close'].values[7:] - forecasts) / data['Close'].values[7:]).sum() / len(forecasts))
Worse still, the rolling window forecasting ran into errors with fitting the model. This may be due to the nature of the data, or due to overfitting to it. Either way, this isn’t great news.
These results beg the question of what a decent model would be for this data. One convenient way of searching for an optimal model is to use an Auto ARIMA function which employs a grid search of optimal parameters. Optimality in this case refers to optimizing a measure of fit such as AIC or BIC. While it doesn’t guarantee a globally optimal set of parameters, Auto ARIMA will return a locally optimal set.
import pmdarima as pm
auto_fit = pm.auto_arima(data['Close'].values, start_p=7, start_q=7,
max_p=10, max_q=10,
d=1, trace=True,
error_action='ignore',
suppress_warnings=True,
stepwise=True)
print(auto_fit.summary())
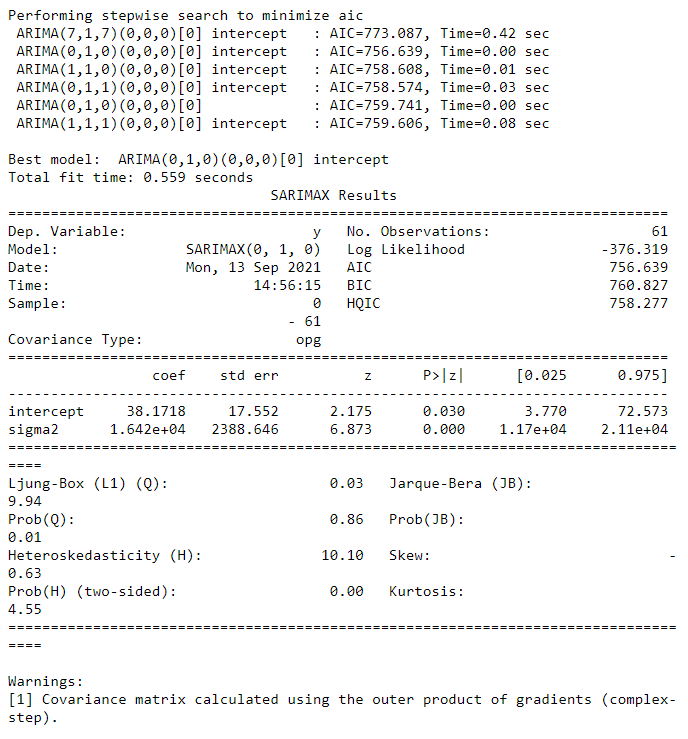
The Auto ARIMA search concluded that an ARIMA(\(0, 1, 0\)) model, or a random walk model has the lowest AIC and is therefore the ideal fit for our data. This is backed up by the computed MAPE:
forecasts = []
for i in range(7, len(data['Close'].values)):
model = sm.tsa.arima.ARIMA(data['Close'].values[:i], order=(0,1,0))
model_res = model.fit()
yhat = model_res.forecast()[0]
forecasts.append(yhat)
print(np.abs((data['Close'].values[7:] - forecasts) / data['Close'].values[7:]).sum() / len(forecasts))

With a lower AIC/BIC and MAPE, the ARIMA(\(0,1,0\)) model is not only a better fit but also a better forecaster. Sometimes the simplest model is the best one to use.
Related Tangents
It turns out that AR and MA use differing diagnostic functions (PACF versus ACF) because the processes are “invertible” if the coefficients are within the unit circle, that is an AR or MA process with finite terms can be reexpressed as an infinite process of the other model. For instance, if we consider the PACF of an (invertible) MA(\(q\)) model, it decays slowly because it is also the PACF of an AR(\(\infty\)) model whose infinite terms prevent any sharp cutoffs. See this Cross Validated post for more mathematical rigor.
One can also approximate an ARIMA(\(p, d, q\)) using an ARMA(\(p+d, q\)) model. This can be seen empirically in this Cross Validated post
Finally, statsmodels actually does not use traditional methods such as MLE or the Yule-Walker equations, but rather something called state space estimation to estimate model parameters. The details of state space models will be in a future post.
References
[1] Nielsen, Aileen. Practical Time Series Analysis. O’Reilly Media, 2019.
[2] Brockwell, Peter; Davis, Richard (2009). Time Series: Theory and Methods (2nd ed.). New York: Springer. ISBN 9781441903198.
[3] https://online.stat.psu.edu/stat510/
[4] https://analyzingalpha.com/interpret-arima-results
[9] https://stats.stackexchange.com/questions/209727/arma-when-arima-should-be-used
[10] http://www-stat.wharton.upenn.edu/~steele/Courses/956/Resource/YWSourceFiles/YW-Eshel.pdf